Some cool features you may not know about Apache Kafka
Apache Kafka is a widely distributed event streaming platform. In this article, I won’t explain Apache Kafka fundamentals like what’s a topic, a partition, an offset nor In-Sync Replicas. You can find a lot of resources to learn how Apache Kafka works and its fundamentals. I will present to you some features you may not have heard about.
Metric Reporters
You may already know that Apache Kafka Clients: Producer and Consumer, can be monitored using JMX metrics. You can browse all the JMX metrics exposed for a Consumer here and for a Producer here.
By default, Apache Kafka Clients exposed the JMX Metrics using the class JmxReporter. This class implements the interface MetricsReporter
public interface MetricsReporter extends Reconfigurable, AutoCloseable {
void init(List<KafkaMetric> var1);
void metricChange(KafkaMetric var1);
void metricRemoval(KafkaMetric var1);
void close();
default Set<String> reconfigurableConfigs() {
return Collections.emptySet();
}
default void validateReconfiguration(Map<String, ?> configs) throws ConfigException {
}
default void reconfigure(Map<String, ?> configs) {
}
@Evolving
default void contextChange(MetricsContext metricsContext) {
}
}
And so you can define your own way to expose those Kafka Metrics by implementing this interface and setting the configuration metric.reporters
settings.put(ConsumerConfig.METRIC_REPORTER_CLASSES_CONFIG, List.of(MyMetricReporter.class));
Client Interceptor
Client Interceptor lets you intercept received or produced records and possibly mutate them. For each Apache Kafka Clients: Producer and Consumer, you can define interceptor classes.
For the producer, you have to implement the interface ProducerInterceptor
public interface ProducerInterceptor<K, V> extends Configurable {
ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
void onAcknowledgement(RecordMetadata var1, Exception exception);
void close();
}
For the consumer, it’s the interface ConsumerInterceptor
public interface ConsumerInterceptor<K, V> extends Configurable, AutoCloseable {
ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);
void onCommit(Map<TopicPartition, OffsetAndMetadata> partitions);
void close();
}
Once you have implemented those interfaces, add your interceptors to the client using the configuration interceptor.classes.
settings.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
List.of(MyConsumerInterceptor.class));
This is particularly useful if you use Apache Kafka in a microservices architecture and you want to add tracing supervision. For example, using OpenTracing you can take a look at opentracing-contrib/java-kafka-client that provides TracingProducerInterceptor and TracingConsumerInterceptor. Those interceptors inject and retrieve span context from record headers.
Partition Assignment & Co-partitioning
Let’s say you have 10 topics, each topic has 1 partition and you create a consumer group with 10 consumer instances. How will the consumers assign each partition? You may suppose that one consumer consumes one partition…In fact, it depends on the strategy used to assign the partitions amongst the consumer instances.
By default, the consumers are configured to use the RangeAssignor. This strategy’s goal is to co-localized the partitions of each subscribed topic to the same consumer. And so, to answer the first question, one consumer will be assigned to all the partitions and the other consumers remaining will be idle.
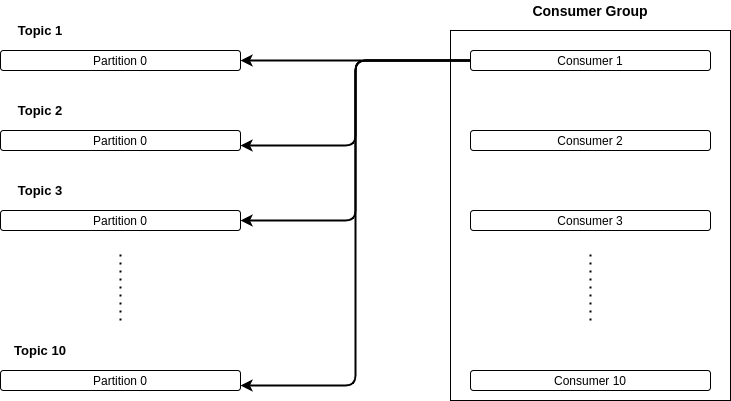
This strategy used by default is designed to be used with co-partitioning topics. Co-partitioning topics are topics with the same number of partitions and where messages are produced with the same partitioner and the same partitioning key.
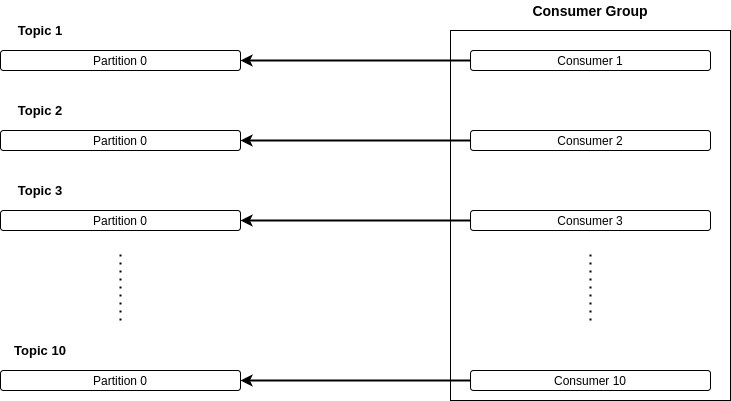
However, if your goal is to maximize the number of consumers used in your consumer group, you should change the default assignment strategy using the property partition.assignment.strategy to use the RoundRobinAssignor
Rack Awareness
By specifying the property broker.rack on each broker of the cluster, Apache Kafka will spread replicas of the same partition across all the specified racks. This feature limits the risk of data loss if a rack goes down. A rack can be a cloud provider zone or a data center location.
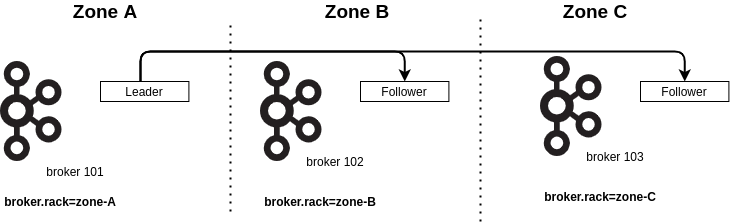
However, Apache Kafka clients always interact with the partition leader, so it can be a problem if your clients are located in a different zone from the broker leader.
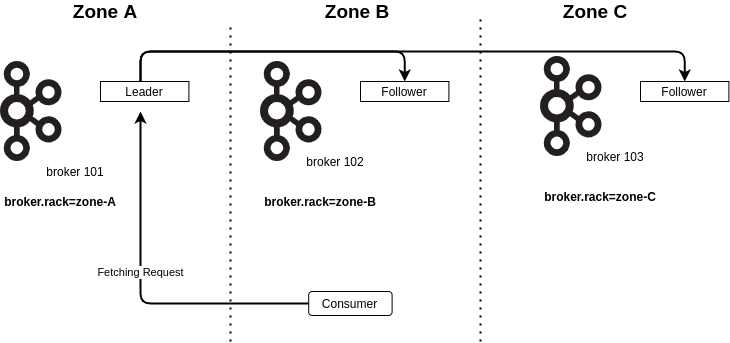
In this diagram, the consumer is located in zone-B, and the partition leader is located in zone-A. It increases the number of cross-zone requests and can increase the billing at some cloud providers.
To avoid this issue, Apache Kafka 2.4 introduces the notion of Follower-Fetching. It means that a consumer can fetch data directly from a follower instead of from the partition leader. To enable this feature, brokers have to set the property broker.rack with the desired location and replica.selector.class with org.apache.kafka.common.replica.RackAwareReplicaSelector. On the other hand, Consumers have to set client.rack to tell in which location they are.
Kafka Lag Exporter
Kafka Lag Exporter is not part of the Apache Kafka project nor the Confluent Platform. It’s an open-source project under Apache-2.0 License to export Consumer Lag with reporters like Prometheus, Graphite, or InfluxDB. Kafka Lag Exporter enables to monitor Consumer Lag but it also allows to estimate the Time Lag. This metric shows how far a Consumer group is behind the last produced record in terms of time. It shows the actual latency of a consumer application. For more information about this estimation, you can read the chapter of the documentation Estimate Consumer Group Time Lag
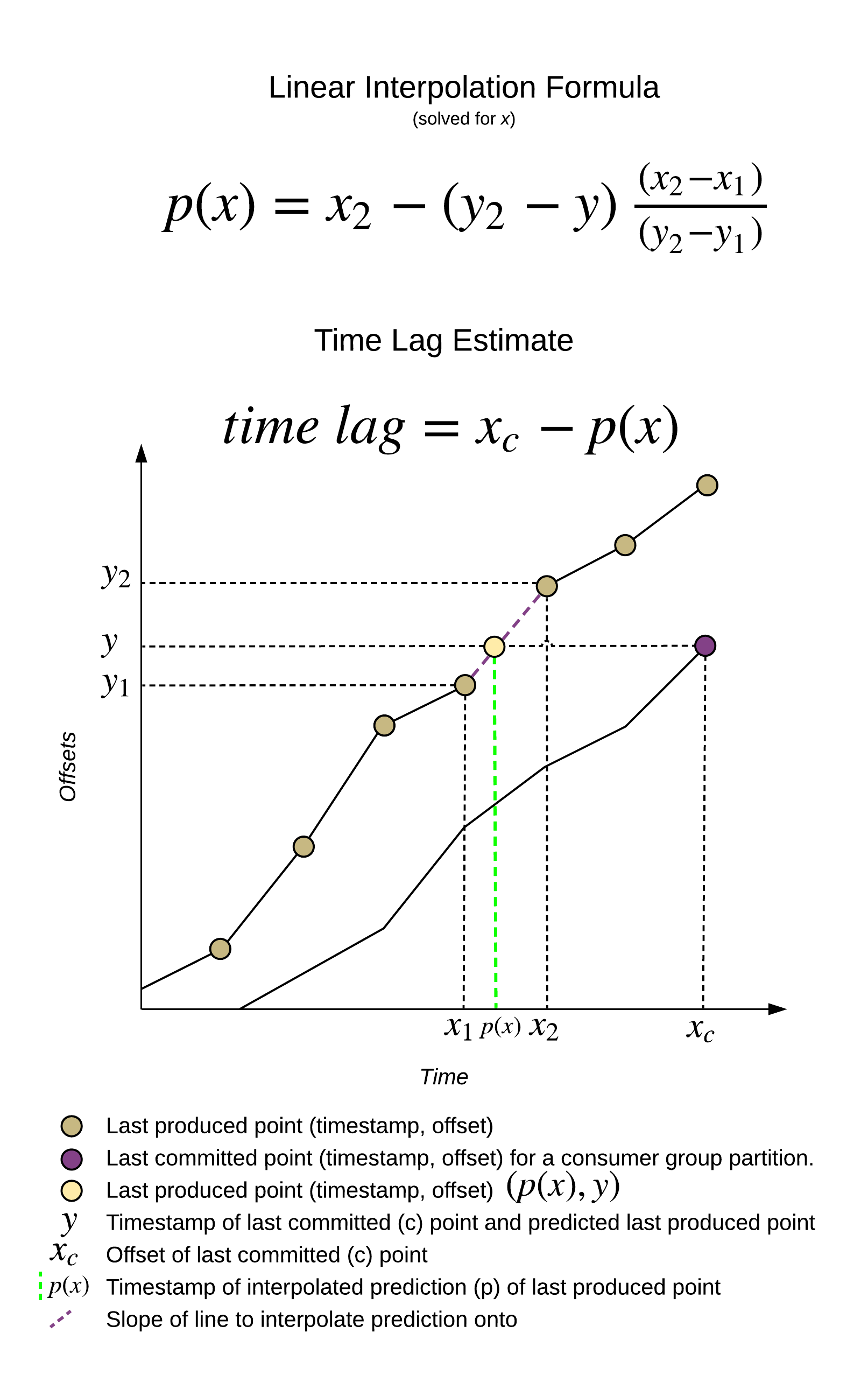
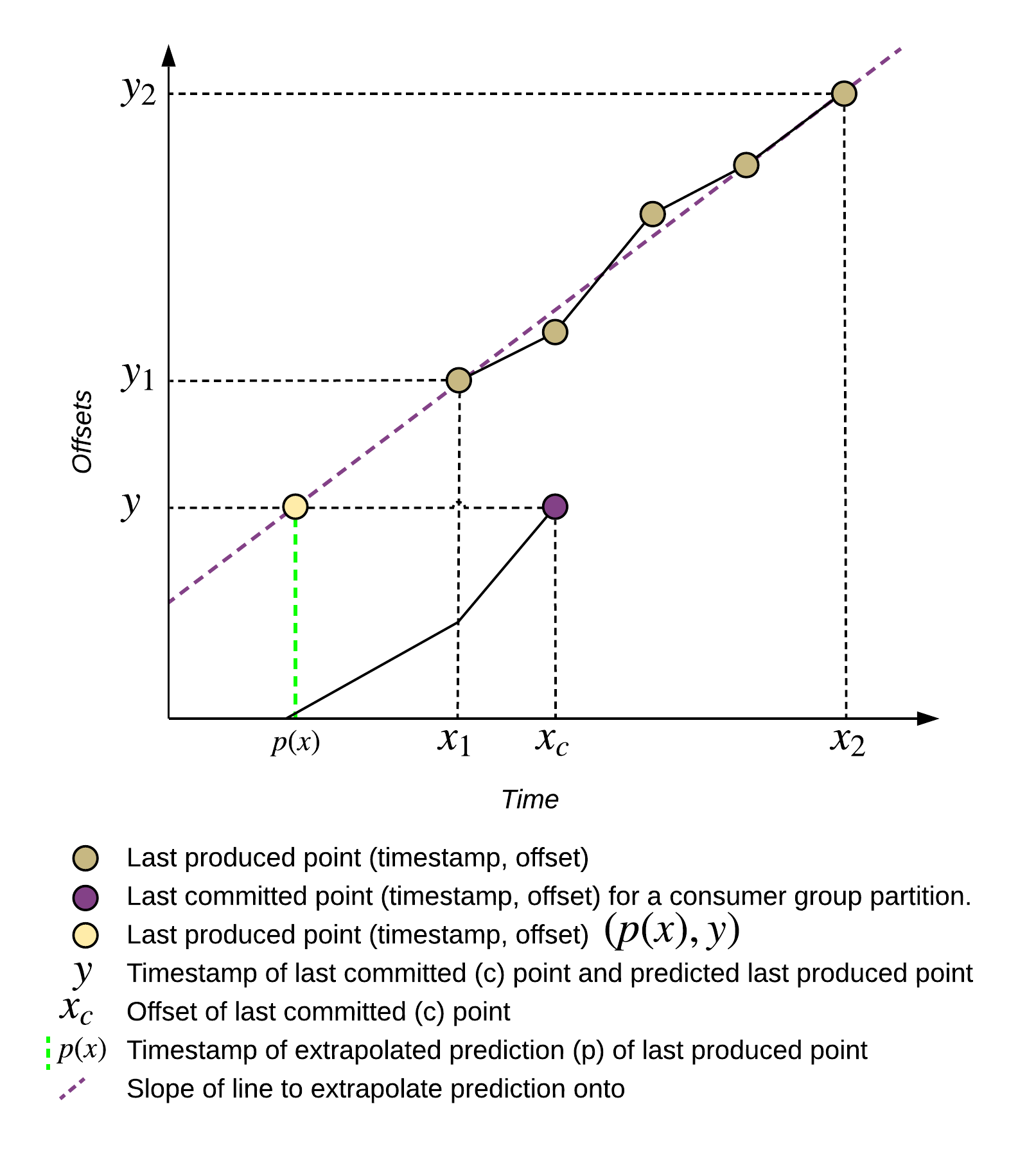
Cluster Linking
In a Multi Data Center architecture, Cluster Linking is the ability to create a link between two distincts Apache Kafka clusters. Once the link is established, you are able to mirror topics. Mirroring a topic means that all the data from a topic and its configuration in the source cluster is replicated to a topic with the same name in the destination cluster.
Unlike, Replicator and MirrorMaker2, Cluster Linking does not require running Connect to move messages from one cluster to another, ensuring that the offsets are preserved from one cluster to another. We call this “byte-for-byte” replication. Whatever is on the source, will be mirrored precisely on the destination cluster. https://docs.confluent.io/platform/current/multi-dc-deployments/cluster-linking/index.html
The destination topic does a “byte-for-byte” replication, it preserves the offsets from one cluster to another and it also replicates source topic configuration like retention, number of partitions from the source topic.
Cluster Linking is a really promising feature but it’s currently a preview feature.
A preview feature is a component of the Confluent Platform that is being introduced to gain early feedback from developers. This feature can be used for evaluation and non-production testing purposes or to provide feedback to Confluent.
Confluent provides a demonstration project to play with this feature.
Tiered Storage
Tiered Storage is the ability to store the data into external storage instead of the local disk of your brokers. The idea is to separate the concerns of data storage from the concerns of data processing. It allows you to retain your data for months, years, or indefinitely.
You can configure your Apache Kafka cluster with one of the three supported tiered storage: AWS S3, GCP GCS, and Pure Storage FlashBlade.
For example with Amazon S3:
confluent.tier.feature=true
confluent.tier.enable=true
confluent.tier.backend=S3
confluent.tier.s3.bucket=<BUCKET_NAME>
confluent.tier.s3.region=<REGION>
And then you can create a topic with tiered storage
kafka-topics --bootstrap-server localhost:9092 \
--create --topic tiered-storage-topic \
--partitions 6 \
--replication-factor 3 \
--config confluent.tier.enable=true \
--config confluent.tier.local.hotset.ms=3600000 \
--config retention.ms=604800000
retention.ms works the same as a normal topic. It defines the time you want to keep your data in the local storage or in the tiered storage.
confluent.tier.local.hotset.ms defines the time in milliseconds a non-active segment is retained on the local storage. Once it’s expired, the segment is deleted from the local storage and saved to the tiered storage.
References
- https://docs.confluent.io/platform/current/kafka/post-deployment.html#balancing-replicas-across-racks
- https://docs.confluent.io/platform/current/multi-dc-deployments/cluster-linking/index.html
- https://docs.confluent.io/platform/current/multi-dc-deployments/multi-region.html#follower-fetching
- https://github.com/lightbend/kafka-lag-exporter#estimate-consumer-group-time-lag
- https://docs.confluent.io/platform/current/multi-dc-deployments/cluster-linking/tutorial.html
- https://docs.confluent.io/platform/current/kafka/tiered-storage.html