Take over Legacy: take back control!
Introduction
I always like to work with legacy applications. First of all, it means that the application is currently being used and running in production. Maybe I’m not working with the most hyped technology nor framework but it means that I’m bringing value to final users and I’m contributing to improve their user experience. In addition, working with a legacy application is most of the time a wide-ranging challenge. With technical problems comes human and company challenges and in my opinion, this is where AI code generators find their limits.
So how do we know we are facing a legacy application or legacy code? There are some classic hints:
- some famous code smells like primitive obsession, large class, long parameter list… etc.
- no or few automated tests.
- some old-fashioned technologies with security issues that are hard to update.
- and more.
Some others symptoms may ring a bell too:
- a production release is seen as risky and it’s a special event for the team
- coding a new feature leads to a regression in other functionalities of the application
- developer's estimations look huge event for a small change
- when you ask your Product Owner at what price they would be willing to give up on a new feature
It’s a non-exhaustive list and each developer or team could have a different point of view of what is legacy code. DORA’s metrics are a good way to start.
A lot of people may think that a good way to get rid of a legacy application is to rewrite it from scratch. In fact, what makes us think that our problems dealing with a legacy application are only based on technology. Write code smells, don’t write automated tests are practices not related to the technology used. What makes us think that this time, the code will be cleaner despite the fact that the team hasn't changed its practices?
Rewriting from scratch is, from my humble point of view, a bad idea. In fact, the team has to take back control of the application by changing its practices and using software crafting.
My experience
Here's my current experience of a legacy project where I have worked for one year and where we are working to take back control.
Disclaimer!
I’m not writing this post to shame people. Its purpose is only to highlight issues to improve.
Automated test yes! But without assertion!

When management is asking you to have a high code coverage rate, what is the first thing that comes to your mind? Create automated tests without assertion to have a good code coverage of course! In my humble opinion, this is professional misconduct and more of a curse than blessing for the people that are working with the project. First of all, your code coverage is now false and gives you a wrong idea of what part of the code is covered. Some may start a refactoring thinking that the code is well tested. Second of all, tests without assertion are dead weight. They are not bringing any value. The team has to maintain them and furthermore executing those tests is time consuming and resource consuming.
The most unpleasant part is that our analysis tool to compute code coverage is not able to detect tests without assertion.
To take back control here, we can:
- delete all the tests without assertion. It will lead to less code to compile, to execute and to maintain and the code coverage rate will now give a real value.
- Another solution is to fix the tests without assertion. Understand what those tests are doing, complete the scenario and add relevant assertions. It’s time consuming, but an important task.
It’s not finished yet! We need to consider that even the tests with assertions are not relevant. To ensure that our tests are robust and reliable, we can rely on mutation testing. It gives a good view of our test’s quality. Finally, it’s really important to take care of our test code base as much as our production code base.
a bug == a test !
Writing a test to start fixing a bug is a practice that should be widespread between developers. It enables you to reproduce the bug and makes sure it won’t occur again.
This is common sense but unfortunately, I had to hammer it home during recent discussions. Some developers were claiming that the code is already covered by some tests, so there was no need to write a new test.
Technical migration
Taking back control also means migrating to modern and battle-tested technologies. Popular technologies are also well known by the developers and most of the time improve their developer experience. Popular technologies enable us to hire more easily. In our case, the application was built using the framework Apache TomEE. This framework was a real pain to work with. It lacks documentation and online resources. It is complex to deal with external properties. It is difficult to write integration tests and to integrate it with the Java ecosystem. So, we decided to migrate to the framework Spring Boot.
In order to migrate and to take back control, we decided to migrate endpoint by endpoint. Each migrated endpoint should be migrated with a successfully running test. By migrating one endpoint at a time, we had to pull the dependencies, transform some classes to Spring bean, upgrade libraries, and make sure the application is still running properly during the migration. Doing things this way let us build a solid base of functional tests.
This migration was long and tough but having working tests at each baby step let us move forward calmly ensuring that we were going into the right direction. During the migration from OpenJPA towardsHibernate, there was one thing that took my breath away! Hibernate was failing to start because an annotated class with @Entity had two fields annotated with the same @Column! Hibernate was totally right to fail because of this…OpenJPA let it go.
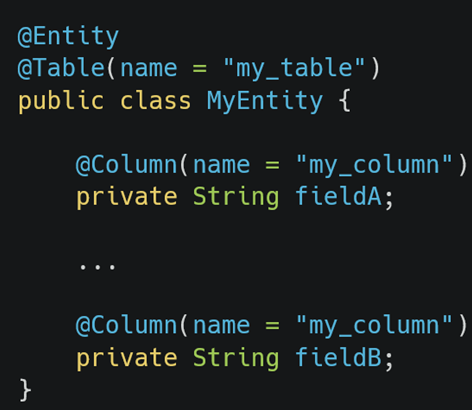
To sum up, it means that we had in our database a column of a table that was used by two different fields of the same Java entity.
A fresh look?
Working with a legacy application also means taking ownership of it and understanding it. The deeper you go, the more you are able to understand how and why some things have been developed and means you are able to change or improve it. For instance, the build of the Docker image is made on a CI where the version of a dependency was added manually. I tried to understand why this dependency was mandatory and I realized that this dependency was in fact empty and totally unnecessary! A classic example of a cargo cult.
Stability versus Speed?
Dealing with a legacy application usually means working with a fragile application and people tend to test, test again and test again and again to make sure the new version won’t break anything. The team fears side effects and each deployment is seen as a special event. It’s easy to understand this way of doing but in fact it suffers from bias.
The book “Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations defines four metrics:
- two metrics of speed: lead time and deployment frequency.
- two metrics of stability: mean time to repair (MTTR) and change failure rate.
And the most important thing to know is that those metrics change together. One can not increase its stability without increasing its speed and the opposite is also true. It’s a common misconception that increasing deployment frequency compromises stability. The Book’s research denies this myth and demonstrates that continuous integration, testing, automation and continuous deployment improves velocity and reliability.
Some best practices
Taking back control is not only about technical topics. It goes with practice and continuous improvement. For example, here’s a list of some best practices we put in place:
- pair programming sessions,
- thorough code review,
- mentoring to help staff master writing automated tests,
- mentoring to deal with legacy code and code that is hard to unit test using golden master testing method,
- a weekly session to discuss our technical debt and how to get rid of it,
- supporting staff to adapt to best practices through sharing at talks and conferences.
Moreover, it’s important to focus on people who really want to improve. It could be a waste of time and really frustrating to invest time and energy without output.
What about AI?
I would like to finish this post about the impact of AI. AI enables us to understand and work with functions even 2000 lines long. AI enables us to clean up and to support our test code base. However, AI is not a silver bullet. It needs to be assisted by best practices, work in baby steps and with generated code that should always be verified. It’s easy to ask AI to generate a test suite over legacy code but be careful with the results! While our AI takes its inspiration from the existing code, it is mandatory to prepare it with best practices and examples.
Using AI to work with a complex legacy code base is like working with a 4-year-old child! You always have to repeat the context, force it to stay focused, remind it what the goal is, and always verify the output.